Neural Network Series: Is binary classification the best you can do? (Part IV)
Something worth noting from the perceptron previously explained, is that the activation function is the element restricting the neuron’s output. Following this idea, what happens if we change it? Would the perceptron’s representation power change? Indeed, that is exactly what Widrow and Hoff proposed with their Adaptive Linear Element proposal.

Linear Regression
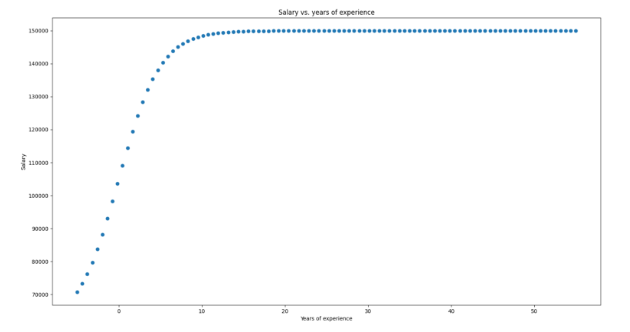
In this scenario, we are choosing the identity function y(x)=x as the perceptron’s activation. As a consequence, the neuron’s output can be any real number. It is important to notice that the activation function is linear, meaning the outputs will follow a linear relationship, which opens the door to tackle other problems, such as linear regression. Below, there’s an image representing a hyperplane approximating the expected salary, based on age and years of experience.

We now face the same problem McCulloch and Pitts did: finding the right weights to represent the hyperplane. Luckily, we can re-use Rosenblatt’s pereptron algorithm by changing the update rule (because it is adjusted to the step activation function).
Optimization methods making their entrance
As before, we need an update rule to make improvements on the weights’ values since, a priori, we don’t have information about the best way of choosing them.
In the image below, we have a step by step explanation of what has changed. Do not get deceived by its apparent complexity! The delta w, indicating the update, will be the negative (-) of the error function’s gradient.
The error function was used as an indicator of how well the perceptron is doing. If the returned value is high, we should continue training. For regression problems, we’ll use the mean square difference between the expected output and the neuron’s output. The error, then, for the entire perceptron, is to sum the individual errors for all the samples in the dataset and we are interested in expressing it in terms of the neuron’s weights.

How does the update rule make sense then? The important thing to remember is that the gradient gives the direction of maximum growth for a function. If we were to move in that direction, we would increase the neuron’s error. In the update rule, the negative indicates that we want to move in the opposite direction, thus decreasing the error. The learning rate, same as before, regulates the step with which we move towards a better solution.

The figure above shows an example of how the error function could look like. It has many minimums and, if I’m interested in the perceptron’s achieving the global minimum, I would like an iterative process to find it. The issue with these methods is that we do not have global information about the function’s shape. We start somewhere, in this case, the black dot, and we do not have guarantees that we will end up in the lowest point. Once stuck in a local minimum, the local information the method has could not be enough to get out of it.
The difference between plots is the learning rate magnitude. On the left, it is bigger, which caused the algorithm to converge faster to a less desired solution. On the right, it might’ve taken more steps, but the configuration is better than the one on the left. This is the constant trade-off when training algorithms: performance versus computational cost. We can’t make the learning rate arbitrarily small because the time it takes to arrive to a solution could be too big.
Non Linear Regression… More alternatives to our toolbox!
Now that we know changing the activation function can modify what the perceptron is able to represent, we do not need to stop there. What if we want to approximate a dataset that looks like this?
In this case, we could use the family of sigmoid functions, which are very important in the neural networks’ realm. Everything explained before applies in this case as well. Below, there are a couple options to train a perceptron for non linear relationships.
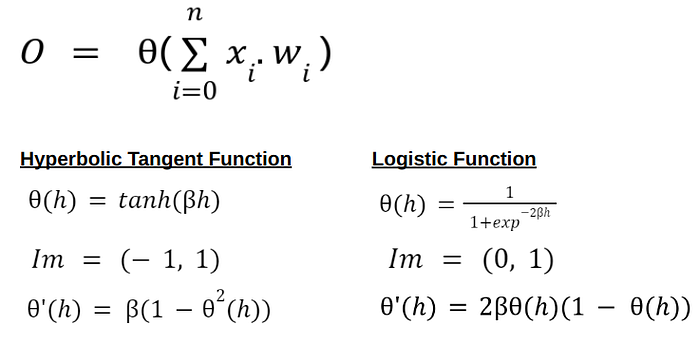
Linear and Non Linear Algorithm
Finally, the algorithm’s body remains the same. In the image, the red areas highlight what needs to change. The epsilon is important because it is highly unlikely the error will drop to zero when dealing with regression problems. On the other hand, the update rule can be used for any activation function that is derivable, by replacing its expression.

We have reached to the end of the perceptron introduction. In the next article, we’ll take a much bigger step, towards the idea of the modern neural network. Stay tunned!
Note: this article was crafted without the use of artificial intelligence technologies. A big part of writing them is an effort to work on my communication skills.
References
[1]: Bernard Widrow and Marcian E. Hoff. (1960). https://www-isl.stanford.edu/~widrow/papers/c1960adaptiveswitching.pdf
